LF Classes#
Summary#
The LF1 and LF2 classes allow for rapid reading of Flood Modeller’s log file format for 1D (.lf1) and 2D (.lf2) simulations. The class must be intiated with the full filepath to a given log file:
from floodmodeller_api import LF1, LF2
lf1 = LF1('path/to/log.lf1')
lf2 = LF2('path/to/log.lf2')
Both the LF1 and LF2 classes are used in the same way.
Warning
Log files will not always be present if simulations are run through the Flood Modeller UI but should be present if run via the API.
Note
As well as reading the log files directly using the LF1 or LF2 classes, you can also get
the log for a simulation directly using the floodmodeller_api.IEF.get_log() method.
Reference#
LF1#
- class floodmodeller_api.LF1(lf_filepath: str | Path | None, steady: bool = False)#
Reads and processes Flood Modeller 1D log file ‘.lf1’
- Parameters:
lf1_filepath (str) – Full filepath to model lf1 file
steady (bool) – True for steady-state simulations
Attributes (unsteady)
- Parameters:
info (dict) – Parameters with one value per simulation
mass_error (pandas.DataFrame) – Mass error
timestep (pandas.DataFrame) – Timestep
elapsed (pandas.DataFrame) – Elapsed
tuflow_vol (pandas.DataFrame) – TUFLOW HPC Vol
tuflow_n_wet (pandas.DataFrame) – TUFLOW HPC nWet
tuflow_dt (pandas.DataFrame) – TUFLOW HPC dt
simulated (pandas.DataFrame) – Simulated
iterations (pandas.DataFrame) – PlotI1
convergence (pandas.DataFrame) – PlotC1
flow (pandas.DataFrame) – PlotF1
Attributes (steady)
- Parameters:
info (dict) – Parameters with one value per simulation
network_iteration (pandas.DataFrame) – Network iteration
largest_change_in_split_from_last_iteration (pandas.DataFrame) – Largest change in split from last iteration
- Output:
Initiates ‘LF1’ class object
- to_dataframe(variable: str = 'all', *, include_tuflow: bool = False) DataFrame#
Collects parameter values that change throughout simulation into a dataframe
- Parameters:
variable (str) – Variable to return, or ‘all’ for all available variables.
include_tuflow (bool) – Include diagnostics for linked TUFLOW models
- Returns:
DataFrame of log file parameters indexed by simulation time (unsteady) or network iterations (steady)
- Return type:
pd.DataFrame
- read(force_reread: bool = False, suppress_final_step: bool = False) None#
Reads log file
- Parameters:
force_reread (bool) – If False, starts reading from where it stopped last time. If True, starts reading from the start of the file.
suppress_final_step (bool) – If False, dataframes and dictionary are not created as attributes.
- report_progress() float#
Returns progress for unsteady simulations
- Returns:
Last progress percentage recorded in log file
- Return type:
float
LF2#
- class floodmodeller_api.LF2(lf_filepath: str | Path | None)#
Reads and processes Flood Modeller 2D log file ‘.lf2’
- Parameters:
lf2_filepath (str) – Full filepath to model lf2 file
Attributes
- Parameters:
info (dict) – Parameters with one value per simulation
simulated (pandas.DataFrame) – Simulated
wet_cells (pandas.DataFrame) – Wet cells
2D_boundary_inflow (pandas.DataFrame) – 2D boundary inflow
2D_boundary_outflow (pandas.DataFrame) – 2D boundary outflow
1D_link_flow (pandas.DataFrame) – 1D link flow
change_in_volume (pandas.DataFrame) – Change in volume
volume (pandas.DataFrame) – Volume
inst_mass_err (pandas.DataFrame) – Inst mass error
mass_error (pandas.DataFrame) – Mass error
largest_cr (pandas.DataFrame) – Largest Cr
elapsed (pandas.DataFrame) – Elapsed
- Output:
Initiates ‘LF2’ class object
- to_dataframe(variable: str = 'all', *, include_tuflow: bool = False) DataFrame#
Collects parameter values that change throughout simulation into a dataframe
- Parameters:
variable (str) – Variable to return, or ‘all’ for all available variables.
include_tuflow (bool) – Include diagnostics for linked TUFLOW models
- Returns:
DataFrame of log file parameters indexed by simulation time (unsteady) or network iterations (steady)
- Return type:
pd.DataFrame
- read(force_reread: bool = False, suppress_final_step: bool = False) None#
Reads log file
- Parameters:
force_reread (bool) – If False, starts reading from where it stopped last time. If True, starts reading from the start of the file.
suppress_final_step (bool) – If False, dataframes and dictionary are not created as attributes.
- report_progress() float#
Returns progress for unsteady simulations
- Returns:
Last progress percentage recorded in log file
- Return type:
float
Examples#
Example 1 - Reading log file and exporting to dataframe
The LF1 class can be used to read a .lf1 file and return the changing parameters as a dataframe.
from floodmodeller_api import LF1
lf1 = LF1("..\\sample_code\\sample_data\\ex3.lf1")
print(lf1.to_dataframe())
This prints the following pandas dataframe object:
mass_error timestep elapsed iter log(dt) convergence_flow convergence_level inflow outflow
simulated
0 days 00:00:00 0.00 0 days 00:00:18.750000 0 days 00:00:01 6.0 4.6 0.0186 0.0004 3.67 2.58
0 days 00:05:00 -0.01 0 days 00:00:37.500000 0 days 00:00:01 5.0 6.2 0.0086 0.0008 3.71 2.69
0 days 00:10:00 -0.04 0 days 00:00:37.500000 0 days 00:00:01 3.0 6.2 0.0036 0.0003 3.75 3.04
0 days 00:15:00 -0.05 0 days 00:01:15 0 days 00:00:01 3.0 7.8 0.0029 0.0002 3.79 3.32
0 days 00:20:00 -0.07 0 days 00:02:30 0 days 00:00:01 3.0 9.4 0.0025 0.0002 3.83 3.50
... ... ... ... ... ... ... ... ... ...
0 days 23:40:00 -0.05 0 days 00:05:00 0 days 00:00:03 3.0 11.0 0.0024 0.0020 22.06 24.25
0 days 23:45:00 -0.04 0 days 00:05:00 0 days 00:00:03 3.0 11.0 0.0025 0.0020 21.30 23.45
0 days 23:50:00 -0.04 0 days 00:05:00 0 days 00:00:03 3.0 11.0 0.0026 0.0020 20.55 22.65
0 days 23:55:00 -0.03 0 days 00:05:00 0 days 00:00:03 3.0 11.0 0.0027 0.0020 19.79 21.86
1 days 00:00:00 -0.03 0 days 00:05:00 0 days 00:00:03 3.0 11.0 0.0028 0.0020 19.04 21.06
Example 2 - Reading log file and printing dictionary
The LF1 class can also be used to directly access the fixed data stored within the .lf1 file, using the info dictionary.
from floodmodeller_api import LF1
lf1 = LF1("..\\sample_code\\sample_data\\ex3.lf1")
print(lf1.info)
This prints the following dictionary:
{
'version': '5.0.0.7752',
'qtol': 0.01,
'htol': 0.01,
'start_time': datetime.timedelta(0),
'end_time': datetime.timedelta(days=1),
'ran_at': datetime.datetime(2021, 9, 8, 12, 18, 21),
'max_itr': 11.0,
'min_itr': 3.0,
'progress': 100.0,
'EFT': datetime.time(12, 18, 24),
'ETR': datetime.timedelta(0),
'simulation_time_elapsed': datetime.timedelta(seconds=3),
'number_of_unconverged_timesteps': 0.0,
'proporion_of_simulation_unconverged': 0.0,
'mass_balance_calculated_every': datetime.timedelta(seconds=300),
'initial_volume': 39596.8,
'final_volume': 53229.4,
'total_lat_link_outflow': 0.0,
'max_system_volume': 270549.0,
'max_volume_increase': 230952.0,
'max_boundary_inflow': 129.956,
'max_boundary_outflow': 127.874,
'net_volume_increase': 13632.6,
'net_inflow_volume': 13709.5,
'volume_discrepancy': 76.8984,
'mass_balance_error': -0.03,
'mass_balance_error_2': -0.0
}
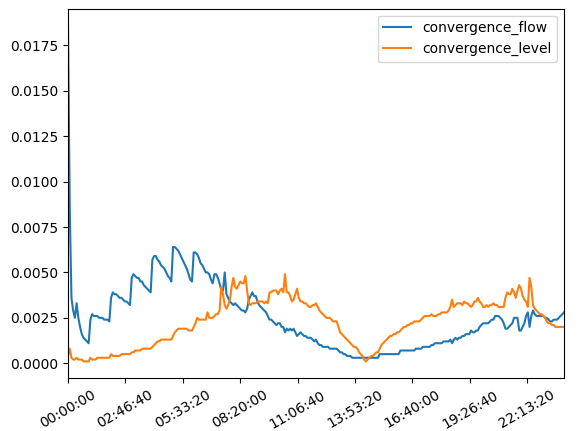
Example 3 - Plotting convergence
The dataframe attributes of LF1 can be easily plotted.
from floodmodeller_api import LF1
import matplotlib.pyplot as plt
lf1 = LF1("..\\sample_code\\sample_data\\ex3.lf1")
lf.convergence.plot()
plt.savefig("convergence.png")
Example 4 - Reading TUFLOW HPC
The LF1 class also includes information from linked TUFLOW HPC models.
This will be included in the info attribute automatically, and can be included in the dataframe via the include_tuflow argument.
from floodmodeller_api import LF1
lf1 = LF1("path/to/log.lf1")
print(lf1.to_dataframe(include_tuflow=True))
print(lf1.info)