DAT Class#
Summary#
The DAT class is used to read, write and update Flood Modeller’s dat file format. The class
is initiated with the filepath of a DAT file (full path or a relative path) to load an existing
network. Alternatively,a new dat file can be created in memory by simply calling DAT() without
passing in a file path.
In [1]: from floodmodeller_api import DAT
In [2]: DAT("network.dat") # read dat from file path
Out[2]: <floodmodeller_api Class: DAT(filepath=network.dat)>
In [3]: DAT() # create a new blank dat file in memory
Out[3]: <floodmodeller_api Class: DAT(filepath=<in_memory>)>
Once you have initialised a DAT class, the various units can be accessed via the attributes:
.sections(see: Section units).conduits(see: Conduit units).structures(see: Structure units).boundaries(see: Boundary units).losses(see: Loss units)
In each, the units are stored in a dictionary of unit names and unit classes. Only units which are supported in the API will be accesible via these attributes, all of which can be found in the Individual Unit Classes section.
In [4]: dat = DAT("EX18.DAT")
In [5]: dat.sections
Out[5]:
{'S1': <floodmodeller_api Unit Class: RIVER(name=S1, type=SECTION)>,
'S2': <floodmodeller_api Unit Class: RIVER(name=S2, type=SECTION)>,
'C2_R1': <floodmodeller_api Unit Class: REPLICATE(name=C2_R1)>,
'C2_R2': <floodmodeller_api Unit Class: REPLICATE(name=C2_R2)>,
'C2_R3': <floodmodeller_api Unit Class: REPLICATE(name=C2_R3)>,
'C2_R4': <floodmodeller_api Unit Class: REPLICATE(name=C2_R4)>,
'C2_R5': <floodmodeller_api Unit Class: REPLICATE(name=C2_R5)>,
'C2_R6': <floodmodeller_api Unit Class: REPLICATE(name=C2_R6)>,
'C2_R7': <floodmodeller_api Unit Class: REPLICATE(name=C2_R7)>,
'C2_R8': <floodmodeller_api Unit Class: REPLICATE(name=C2_R8)>,
'C2_R9': <floodmodeller_api Unit Class: REPLICATE(name=C2_R9)>,
'C2_R10': <floodmodeller_api Unit Class: REPLICATE(name=C2_R10)>,
'S3': <floodmodeller_api Unit Class: RIVER(name=S3, type=SECTION)>,
'S4': <floodmodeller_api Unit Class: RIVER(name=S4, type=SECTION)>,
'S5': <floodmodeller_api Unit Class: RIVER(name=S5, type=SECTION)>,
'S6': <floodmodeller_api Unit Class: RIVER(name=S6, type=SECTION)>,
'S7': <floodmodeller_api Unit Class: RIVER(name=S7, type=SECTION)>,
'S8': <floodmodeller_api Unit Class: RIVER(name=S8, type=SECTION)>}
In [6]: dat.conduits
Out[6]:
{'C2': <floodmodeller_api Unit Class: CONDUIT(name=C2, type=CIRCULAR)>,
'C2m': <floodmodeller_api Unit Class: CONDUIT(name=C2m, type=CIRCULAR)>,
'C2md': <floodmodeller_api Unit Class: CONDUIT(name=C2md, type=CIRCULAR)>,
'C2d': <floodmodeller_api Unit Class: CONDUIT(name=C2d, type=CIRCULAR)>}
In [7]: dat.structures
Out[7]:
{'S0': <floodmodeller_api Unit Class: WEIR(name=S0)>,
'C2d': <floodmodeller_api Unit Class: WEIR(name=C2d)>,
'S4': <floodmodeller_api Unit Class: WEIR(name=S4)>,
'S8': <floodmodeller_api Unit Class: WEIR(name=S8)>,
'S3LS': <floodmodeller_api Unit Class: SPILL(name=S3LS)>}
In [8]: dat.boundaries
Out[8]:
{'QT1': <floodmodeller_api Unit Class: QTBDY(name=QT1)>,
'QT2': <floodmodeller_api Unit Class: QTBDY(name=QT2)>,
'S1d': <floodmodeller_api Unit Class: QTBDY(name=S1d)>,
'C2mH': <floodmodeller_api Unit Class: HTBDY(name=C2mH)>,
'P_del': <floodmodeller_api Unit Class: HTBDY(name=P_del)>,
'S9': <floodmodeller_api Unit Class: HTBDY(name=S9)>}
In [9]: dat.losses
Out[9]: {'S2': <floodmodeller_api Unit Class: CULVERT(name=S2, type=INLET)>}
Each individual unit class is somewhat unique in how they can be worked with in python, but generally
most unit classes will have a .name, .comment and .data attribute.
For example, a RIVER unit class contains the full section data as a dataframe:
In [10]: dat.sections["S3"].data # Accessing the section data for river section 'S3'
Out[10]:
X Y Mannings n Panel ... Easting Northing Deactivation SP. Marker
0 0.0 20.0 0.03 False ... 0.0 0.0 0
1 0.1 18.0 0.03 False ... 0.0 0.0 0
2 1.0 18.0 0.03 False ... 0.0 0.0 0
3 2.0 18.0 0.03 False ... 0.0 0.0 0
4 2.1 20.0 0.03 False ... 0.0 0.0 0
[5 rows x 10 columns]
All other associated data can be accessed and edited for a RIVER unit class via class attributes,
for example the ‘distance to next section’ can be accessed using the .dist_to_next attribute:
In [11]: dat.sections["S3"].dist_to_next # print the distance to next section for river section 'S3'
Out[11]: 100.0
In [12]: dat.sections["S3"].dist_to_next = 150.0 # Update the distance to next section to 150m
It is possible to call the next() and prev()
methods on a unit of any class to find the next or previous units in the reach:
In [13]: dat.next(dat.sections["S3"])
Out[13]: <floodmodeller_api Unit Class: RIVER(name=S4, type=SECTION)>
You can use insert_unit() and remove_unit()
to insert or remove one unit at a time from the dat file.
unit_S6 = dat.sections["S6"]
dat.remove_unit(unit_S6) # remove unit S6 from dat file
dat.insert_unit(unit_S6, add_after = dat.sections["S5"]) # add unit back into dat file
from floodmodeller_api.units import RIVER
dat.insert_unit(RIVER(name="new_unit"), add_at=-1) # insert a blank river section at the end
To insert multiple units at once, use the insert_units() method.
In [14]: from floodmodeller_api.units import RIVER
....: blank_dat = DAT() # create a blank DAT instance
....: blank_dat.sections # currently empty
....:
Out[14]: {}
In [15]: new_sections = [RIVER(name=f"section_{i:>02}") for i in range(5)] # Create 5 new section units
....: blank_dat.insert_units(new_sections, add_at=-1) # insert all the units
....: blank_dat.sections
....:
Out[15]:
{'section_00': <floodmodeller_api Unit Class: RIVER(name=section_00, type=SECTION)>,
'section_01': <floodmodeller_api Unit Class: RIVER(name=section_01, type=SECTION)>,
'section_02': <floodmodeller_api Unit Class: RIVER(name=section_02, type=SECTION)>,
'section_03': <floodmodeller_api Unit Class: RIVER(name=section_03, type=SECTION)>,
'section_04': <floodmodeller_api Unit Class: RIVER(name=section_04, type=SECTION)>}
Although it is possible to rename units by passing a new name into the .name attribute,
it is recommended to avoid this as it may cause label issues within the network.
For units that are not currently supported in the API, limited read-only access can be found
in the ._unsupported attribute, where unit names, types and labels can be accessed.
The DAT representation of an unsupported unit can accessed but cannot be edited.
In [16]: dat._unsupported
Out[16]:
{'C2m (MANHOLE)': <floodmodeller_api Unit Class: MANHOLE(name=C2m, type=False)>,
'P_suc (OCPUMP)': <floodmodeller_api Unit Class: OCPUMP(name=P_suc, type=False)>}
In [17]: print(dat._unsupported["P_suc (OCPUMP)"]) # printing a unit will show its DAT representation
OCPUMP
P_suc P_del
730.000 19.000 0.200 0.600
LOGICAL
TRIGGER MODE
3HOURS EXTEND
0.000 MANUAL STOPPED
2.500 MANUAL ON
8.000 MANUAL STOPPED
HEAD FLOW EFFICIENCY
3
17.600 0.100 0.550
19.000 0.200 0.600
20.000 0.300 0.550
RULES
3 0.000HOURS EXTEND
Rule1
IF(LEVEL(S3).LT.18.3)
THEN PUMP=STOPPED
END
Rule2
IF(LEVEL(S6).GT.21.5)
THEN PUMP=STOPPED
END
Rule3
IF(LEVEL(S3).GT.20.3)
THEN PUMP=ON
END
TIME RULE DATA SET
2
0.000ALL
999.000ALL
In addition to the units, the general parameters for the DAT file can be accessed through
the .general_parameters attribute. This contains a dictionary of all the general
DAT settings and can be edited by assigning them new values.
Warning
Only change values in the general parameters which you are sure can be edited. For example, ‘Node Count’ should be treated as read-only
In [18]: dat.general_parameters # Access dictionary of general DAT parameters
Out[18]:
{'Node Count': 34,
'Lower Froude': 0.75,
'Upper Froude': 0.9,
'Min Depth': 0.1,
'Convergence Direct': 0.001,
'Units': 'DEFAULT',
'Water Temperature': 10.0,
'Convergence Flow': 0.01,
'Convergence Head': 0.01,
'Mathematical Damping': 0.7,
'Pivotal Choice': 0.1,
'Under-relaxation': 0.7,
'Matrix Dummy': 0.0,
'RAD File': ''}
Conveyance curves#
New in version 0.4.4
Calculated conveyance curves for river sections can now be accessed with the
conveyance() property.
Calculating the conveyance curve of a river cross section can be useful when identifying ‘spikes’ in
the conveyance curve, or looking where panel markers may need to be added. The conveyance curve for
a river unit can be accessed by simply calling conveyance().
For example, to access the conveyance curve and plot it, you could do the following:
import matplotlib.pyplot as plt
# Read in data
dat = DAT("network.dat")
section_data = dat.sections["CSRD10"].data
conveyance_data = dat.sections["CSRD10"].conveyance
def plot_section_with_conveyance(section_data, conveyance_data):
# Set up matplotlib plot
fig, ax1 = plt.subplots()
ax1.plot(section_data.X, section_data.Y, "brown")
ax1.fill_between(section_data.X, section_data.Y, section_data.Y.min() - 0.1, color="brown", alpha=0.5)
ax1.set_xlabel("Chainage (m)", color="brown")
ax1.set_ylabel("Stage (mAOD)")
ax2 = ax1.twiny()
ax2.plot(conveyance_data.values, conveyance_data.index, "b-")
ax2.set_xlabel("Conveyance (m3/s)", color="b")
# display it
plt.show()
# Plot with function
plot_section_with_conveyance(section_data, conveyance_data)
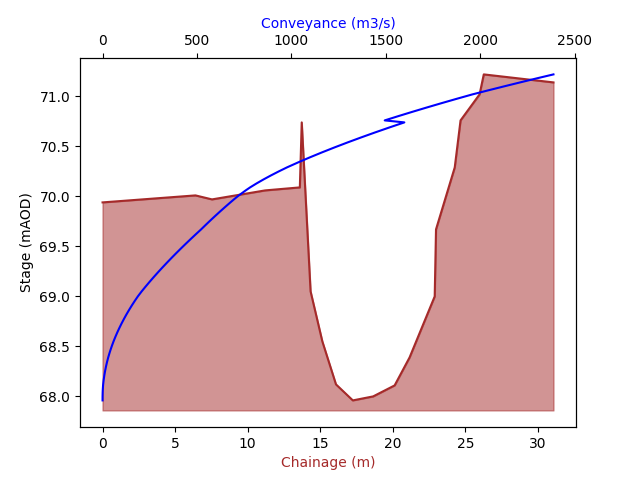
In this example we see a spike in the conveyance at around 70.75mAOD, we can add a panel marker here and see how the conveyance curve is improved:
# Add a panel marker at the point in the section where there is a sharp peak
section_data.loc[section_data.index[5], "Panel"] = True
# recalculate conveyance curve
conveyance_data = dat.sections["CSRD10"].conveyance
# Plot with function
plot_section_with_conveyance(section_data, conveyance_data)
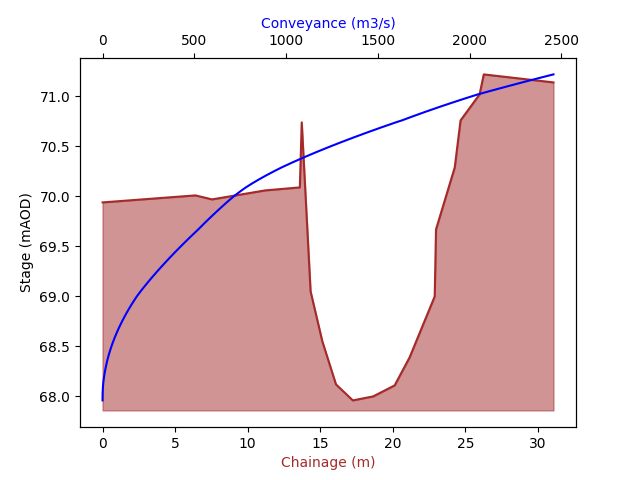
Now we can see that the conveyance curve is improved! With a simple script this process of identifying conveyance spikes and adding panel markers could be automated.
Rules and varrules#
Within a unit, there is also support for logical RULES & VARRULES. There is also support for VARIABLES in the DAT file as well.
Warning
You can only use RULES, VARRULES & VARIABLES if your unit/file actually has them.
dat.structures["MINT_SLu"].rules
>>> {
{"name": "Rule 1", "logic": "IF (LEVEL(KENT06_036...mer=ON\nEND"},
{"name": "Rule 2", "logic": "IF (Level(KENT06_036...ESTART\nEND"},
{"name": "Rule 3", "logic": "IF (Level(KENT06_036...VE = 0\nEND"}
}
dat.structures["MINT_SLu"].varrules
>>> {
{"name": "Varrule 1", "logic": "IF (Level(KENT06_036....RESET\nEND"},
{"name": "Varrule 2", "logic": "IF (Level(KENT06_036....RESET\nEND"}
}
dat.variables.data
>>> {
Index(["name", "type", "initial value", "initial status"], dtype="object")
0: array(["TravelTimer", "TIMER", "0", "0"], dtype=object)
1: array(["DumVar", "integer", "", "n/a"], dtype=object)
}
Reference#
- class floodmodeller_api.DAT(dat_filepath: str | Path | None = None, with_gxy: bool = False, from_json: bool = False)#
Reads and writes Flood Modeller datafile format ‘.dat’
- Parameters:
dat_filepath (str, optional) – Full filepath to dat file. If not specified, a new DAT class will be created. Defaults to None.
with_gxy (bool, optional) – Create an empty GXY when creating a new DAT in memory. Defaults to False.
from_json (bool, optional) – Internal flag used when rebuilding a DAT from JSON. Defaults to False.
- Output:
Initiates ‘DAT’ class object
- Raises:
TypeError – Raised if dat_filepath does not point to a .dat file
FileNotFoundError – Raised if dat_filepath points to a file which does not exist
- update() None#
Updates the existing DAT based on any altered attributes
- save(filepath: str | Path) None#
Saves the DAT to the given location, if pointing to an existing file it will be overwritten. Once saved, the DAT() class will continue working from the saved location, therefore any further calls to DAT.update() will update in the latest saved location rather than the original source DAT used to construct the class
- Parameters:
filepath (str) – Filepath to new save location including the name and ‘.dat’ extension
- Raises:
TypeError – Raised if given filepath doesn’t point to a file suffixed ‘.dat’
- insert_unit(unit: Unit, add_before: Unit | None = None, add_after: Unit | None = None, add_at: int | None = None, defer_update: bool = False) None#
Inserts a unit into the dat file.
- Parameters:
unit (Unit) – FloodModeller unit input.
add_before (Unit) – FloodModeller unit to add before.
add_after (Unit) – FloodModeller unit to add after.
add_at (integer) – Positional argument (starting at 0) of where to add in the dat file. To add at the end of the network you can use -1.
defer_update (bool) – If True, defer rebuilding the DAT structure until a later update.
- Raises:
SyntaxError – Raised if no positional argument is given.
TypeError – Raised if given unit isn’t an instance of FloodModeller Unit.
NameError – Raised if unit name already appears in unit group.
- insert_units(units: list[Unit], add_before: Unit | None = None, add_after: Unit | None = None, add_at: int | None = None) None#
Inserts a list of units into the dat file.
- Parameters:
units (list[Unit]) – List of FloodModeller units.
add_before (Unit) – FloodModeller unit to add before.
add_after (Unit) – FloodModeller unit to add after.
add_at (integer) – Positional argument (starting at 0) of where to add in the dat file. To add at the end of the network you can use -1.
- remove_unit(unit: Unit) None#
Remove a unit from the dat file.
- Parameters:
unit (Unit) – flood modeller unit input.
- Raises:
TypeError – Raised if given unit isn’t an instance of FloodModeller Unit.
- diff(other: DAT, force_print: bool = False) None#
Compares the DAT class against another DAT class to check whether they are equivalent, or if not, what the differences are. Two instances of a DAT class are deemed equivalent if all of their attributes are equal except for the filepath and raw data. For example, two DAT files from different filepaths that had the same data except maybe some differences in decimal places and some default parameters ommitted, would be classed as equivalent as they would produce the same DAT instance and write the exact same data.
The result is printed to the console. If you need to access the returned data, use the method
DAT._get_diff()- Parameters:
other (floodmodeller_api.DAT) – Other instance of a DAT class
force_print (bool) – Forces the API to print every difference found, rather than just the first 25 differences. Defaults to False.
- next(unit: Unit) Unit | list[Unit] | None#
Finds next unit in the reach.
- Next unit in reach can be infered by:
The next unit in the .dat file structure - such as when a river section has a positive distance to next The units with the exact same name - such as a junction unit The next unit as described in the ds_label - such as with Bridge units
- Parameters:
unit (Unit) – flood modeller unit input.
- Returns:
Flood modeller unit either on its own or in a list if more than one follows in reach.
- Return type:
Union[Unit, list[Unit], None]
- prev(unit: Unit) Unit | list[Unit] | None#
Finds previous unit in the reach.
- Previous unit in reach can be infered by:
The previous unit in the .dat file structure - such as when the previous river section has a positive distance to next. The units with the exact same name - such as a junction unit The previous unit as linked through upstream and downstream labels - such as with Bridge units
- Parameters:
unit (Unit) – flood modeller unit input.
- Returns:
Flood modeller unit either on its own or in a list if more than one follows in reach.
- Return type:
Union[Unit, list[Unit], None]
- to_json() str#
Converts the object instance into a JSON string representation.
- Returns:
A JSON string representing the object instance.
- Return type:
str
- classmethod from_json(json_string: str)#
Creates an object instance from a JSON string.
- Parameters:
json_string (str) – A JSON string representation of the object.
- Returns:
An object instance of the class.
- get_network() tuple[list[Unit], list[tuple[Unit, ...]]]#
Generates a network representation of units and their connections.
This method creates a directed network where nodes represent units and edges represent labeled connections between them. The edges are directional, determined by the order of appearance in the .dat file.
It’s possible that the relationships defined by the edges define multiple networks since it is possible for a dat file to define multiple networks. Such models might have a 2D model which joins them together, but the 2D model is not represented as a unit in the network graph.
- Returns:
A list of Unit objects representing the nodes.
A list of tuples, each containing two Unit objects representing a directed edge.
- Return type:
tuple[list[Unit], list[tuple[Unit, …]]]
Examples#
Example 1 - Adding 300mm siltation to all river sections
In this example, the cross section data for individual river sections needs to be edited to add 300mm to the lowest bed level and make this the minimum bed level across the entire section. This is a simple method to quickly represent siltation in the channel. The updated DAT file is saved to a new location rather than updating the original file.
# Import modules
from floodmodeller_api import DAT
# Initialise DAT class
dat = DAT("path/to/datafile.dat")
# Iterate through all river sections
for name, section in dat.sections.items():
df = section.data # get section data
min_elevation = df["Y"].min() # Get minimum bed level across section
raised_bed = min_elevation + 0.3 # Define new minimum bed level by adding 0.3m
df["Y"].loc[df["Y"] < raised_bed] = raised_bed # Update any bed levels which are less than the new min bed level
dat.save("path/to/datafile_300mm_siltation.dat") # Save to new location
Example 2 - Inserting multiple units
In this example, multiple units from one DAT file are inserted into another DAT file.
# Import modules
from floodmodeller_api import DAT
# Initialise DAT class
dat_1 = DAT("path/to/datafile1.dat")
dat_2 = DAT("path/to/datafile2.dat")
# Insert units from dat_2 into dat_1
dat_1.insert_units(
units=[dat_2.sections["20"], dat_2.sections["30"]],
add_before=dat_1.sections["P4000"],
)
dat_1.save("path/to/new_datfile1.dat") # Save to new location